یادگیری ماشین یا ماشین لرنینگ تقریباً در هر بخش تجاری کاربردهای خود را پیدا کرده است. چندین الگوریتم در یادگیری ماشین استفاده می شود که به ساخت مدلهای پیچیده کمک می کند. هر یک از این الگوریتمها در یادگیری ماشین را میتوان در دسته بندی خاصی طبقه بندی کرد. در این مقاله از وبسایت هوش مصنوعی آویر با انواع یادگیری ماشین و الگوریتمهای آن آشنا خواهیم شد. این مقاله به شما بینش بهتری در زمینه یادگیری ماشین میدهد. با ما همراه باشید.
یادگیری ماشین چیست؟
یادگیری ماشین یک کاربرد از هوش مصنوعی است که سیستمها را قادر میسازد تا با در اختیار داشتن حجم وسیعی از دادهها آموزش ببینند و مشکلات خاصی را حل کنند. ماشین لرنینگ از الگوریتمهای کامپیوتری استفاده میکند که کارایی آنها را به طور خودکار از طریق تجربه بهبود می بخشد.
یادگیری ماشین اولین بار توسط آرتور ساموئل، یکی از پیشگامان هوش مصنوعی، در شرکت بینالمللی IBM در سال 1959 ابداع شد. از نظر فنی، یادگیری ماشین نوعی هوش مصنوعی است. یادگیری عمیق از شبکههای عصبی مصنوعی استفاده میکند، اما انواع دیگر تکنیکهای یادگیری ماشین معمولاً در عمل و برای آموزش بسیاری از الگوریتمهای یادگیری عمیق استفاده میشوند.
انواع یادگیری ماشین
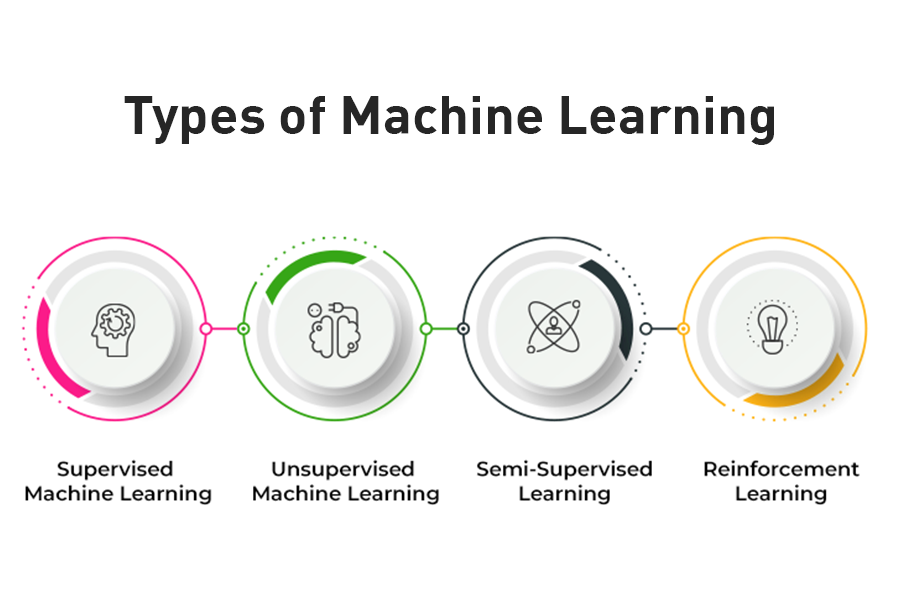
متخصصان معمولاً به چهار نوع اصلی مدلهای یادگیری ماشین با توجه به مناسب بودن آنها برای فرآیندهای مورد استفاده در تنظیم دادهها اشاره میکنند که عبارتند از:
- مدلهای یادگیری با نظارت (Supervised learning)، دادههایی را مصرف میکنند که توسط انسانها از قبل برچسبگذاری شده است.
- مدلهای یادگیری بدون نظارت (Unsupervised learning)، الگوهایی را در دادههایی کشف میکنند که قبلاً برچسبگذاری نشده اند.
- مدلهای یادگیری نیمهنظارتی (Semi-supervised learning)، شامل یک فرآیند تکرار شونده است که با دادههای برچسبدار و بدون برچسب کار میکند.
- مدل های یادگیری تقویتی (Reinforcement Learning) از الگوریتمهایی استفاده میکنند که میتوانند مدلها را در پاسخ به بازخورد در مورد عملکرد پس از استقرار تنظیم کنند.
در ادامه به طور دقیقتر با انواع ماشین لرنینگ آشنا خواهیم شد.
انتخاب مناسبترین نوع از انواع یادگیری ماشین
علم داده با یک فرآیند تجربی و تکراری شروع میشود تا ببیند چه رویکردی از نظر عملکرد، دقت، قابلیت اطمینان و توضیحپذیری ارزشمندتر است. انواع یادگیری ماشین در زمان در نظر گرفتن نقاط قوت و ضعف مختلف یک کلاس معین از الگوریتمها برای یک مشکل خاص بر اساس منشأ دادهها مفید هستند. نظریهپردازان و فعالان حوزه یادگیری ماشین احتمالاً چندین نوع یادگیری ماشین و الگوریتمهای مختلف را در آن انواع ترکیب میکنند تا به بهترین نتیجه دست یابند.
دانشمندان علوم داده، یک مجموعه داده را با استفاده از تکنیکهای بدون نظارت تجزیه و تحلیل کنند تا به درک اساسی از روابط درون یک مجموعه داده دست یابند – به عنوان مثال، چگونه فروش یک محصول با موقعیت آن در قفسه فروشگاه مرتبط است. وقتی این رابطه تأیید شد، متخصصان از تکنیکهای نظارت شده با برچسبهایی استفاده کنند که مکان قفسه محصول را توصیف میکند. تکنیکهای نیمهنظارتشده میتوانند به طور خودکار برچسبهای مکان قفسه را محاسبه کنند. پس از استقرار مدل یادگیری ماشین، یادگیری تقویتی پیشبینیهای مدل را بر اساس فروش واقعی تنظیم میکند.
دیوید گواررا (David Guarrera)، مدیر شرکت EY-Parthenon در راهبردهای کمی و راهکارهای عملی، معتقد است که درک عمیق دادهها ضروری است زیرا این درک به عنوان طرح اولیه پروژه عمل میکند. عملکرد یک مدل یادگیری ماشین جدید به ماهیت دادهها، مشکل خاص و آنچه برای حل آن مشکل نیاز است بستگی دارد.
برای مثال، شبکههای عصبی ممکن است برای کارهای تشخیص اشیا بهترین انتخاب باشند، در حالی که درختهای تصمیم میتوانند برای نوع دیگری از مشکل طبقهبندی مناسبتر باشند. گواررا توضیح داد: “این موضوع معمولاً در مورد یافتن ابزار مناسب برای شغل مناسب در زمینه یادگیری ماشین و در مورد تناسب با بودجه و محدودیت های محاسباتی پروژه است.”
4 نوع رایج انواع یادگیری ماشین عبارتند از:
1. یادگیری با نظارت (Supervised learning)
مدلهای یادگیری نظارت شده (که به اسمهایی مانند یادگیری تحت نظارت یا یادگیری با نظارت هم شناخته میشود) با دادههایی کار میکنند که قبلاً برچسبگذاری شدهاند. پیشرفت اخیر در یادگیری عمیق توسط پروژه استنفورد (Stanford) سرعت گرفت که در سال 2006 افرادی را برای برچسبگذاری تصاویر در پایگاه داده ImageNet استخدام کرد. استفاده از برچسبها بعد از این پروژه مستلزم زمان و تلاش زیادی است. در برخی موارد، این برچسبها میتوانند به طور خودکار به عنوان بخشی از یک فرآیند اتوماسیون، مانند ثبت موقعیت محصولات در یک فروشگاه، تولید شوند. طبقهبندی و رگرسیون رایجترین انواع الگوریتمهای یادگیری تحت نظارت هستند.
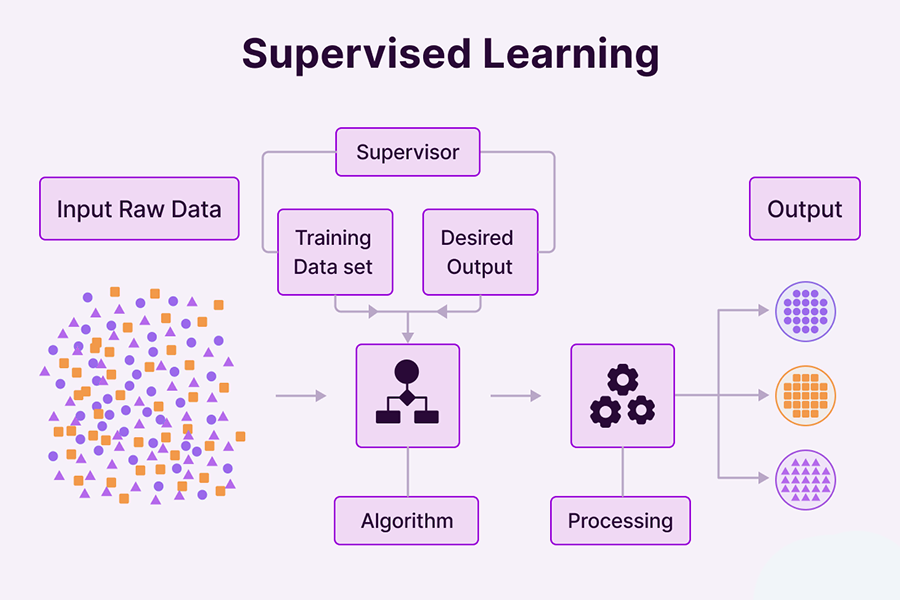
- الگوریتمهای طبقهبندی (Classification algorithms) دستهبندی یک موجودیت، شی یا رویداد را به همان شکلی تعیین میکنند که در دادهها نشان داده شده است. ساده ترین الگوریتمهای طبقهبندی به سوالات باینری مانند بله/خیر، فروختن/نفروختن یا گربه است/گربه نیست پاسخ میدهند. الگوریتمهای پیچیدهتر، اشیا را در دستههای مختلف مانند گربه، سگ یا موش قرار میدهند. الگوریتمهای طبقهبندی محبوب شامل درختهای تصمیم، رگرسیون لجستیک، جنگل تصادفی و ماشینهای بردار پشتیبانی هستند.
- الگوریتمهای رگرسیون (Regression algorithms)، روابط درون متغیرهای متعدد نمایش داده شده در یک مجموعه داده را شناسایی میکنند. این رویکرد در زمان تجزیه و تحلیل این موضوع مفید است که چگونه یک متغیر خاص مانند فروش محصول با متغیرهایی مانند قیمت، دما، روز هفته یا مکان قفسه ارتباط دارد. الگوریتمهای رگرسیون محبوب شامل رگرسیون خطی، رگرسیون چند متغیره، درخت تصمیم و رگرسیون حداقل انقباض مطلق و عملگر انتخاب (رگرسیون لاسو – Lasso Regression) است.
موارد استفاده متداول عبارتند از طبقهبندی تصاویر اشیاء به دستهها، پیشبینی روند فروش، دستهبندی برنامههای وام و استفاده از تعمیر و نگهداری پیشگیرانه برای تخمین میزان شکست.
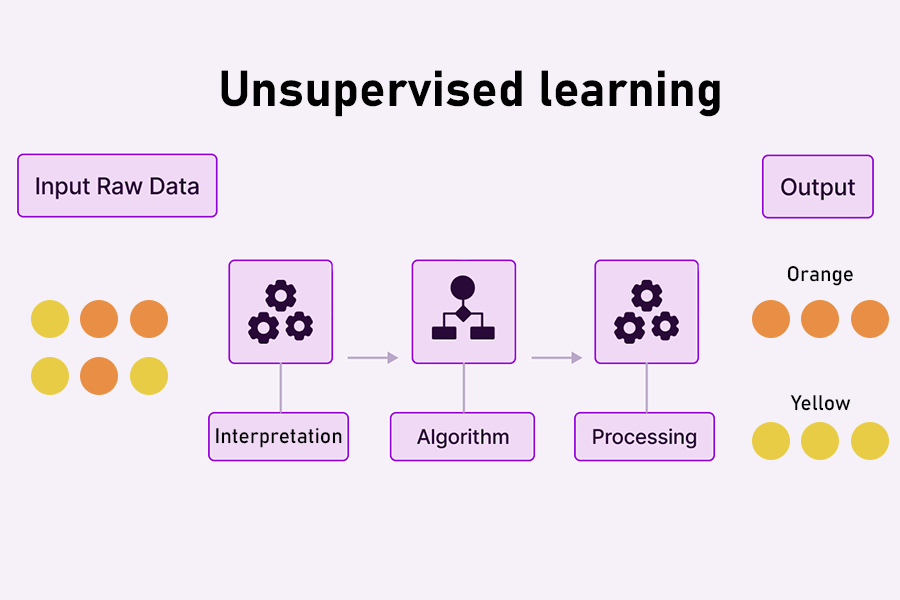
2. یادگیری بدون نظارت (Unsupervised learning)
مدلهای یادگیری بدون نظارت، فرآیند تشخیص الگوهای موجود در یک مجموعه داده را خودکارسازی میکنند. این الگوها به ویژه در تجزیه و تحلیل دادههای اکتشافی برای تعیین بهترین راه برای چارچوب یک مسئله در علم داده مفید هستند. خوشهبندی و کاهش ابعاد، دو نوع الگوریتم رایج در یادگیری بدون نظارت هستند.
- الگوریتمهای خوشهبندی (Clustering algorithms) به گروهبندی مجموعههای مشابه از دادهها بر اساس معیارهای مختلف کمک میکند. متخصصان میتوانند دادهها را به گروههای مختلف تقسیم کنند تا الگوهای درون هر گروه را شناسایی کنند.
- الگوریتمهای کاهش ابعاد (Dimension reduction algorithms)، راههایی را برای فشردهسازی موثر چندین متغیر برای یک مشکل خاص بررسی میکنند.
این الگوریتمها شامل رویکردهایی برای انتخاب ویژگی و طرحریزی هستند. انتخاب ویژگی به اولویتبندی ویژگیهایی کمک می کند که بیشتر به یک مسئله مطرح شده مرتبط هستند. طرحریزی ویژگی، راههایی را برای یافتن روابط عمیقتر بین متغیرهای متعددی بررسی میکند که میتوانند به متغیرهای میانی جدید کمیتسازی شوند؛ متغیرهای میانی جدیدی که برای مسئله مورد نظر مناسبتر هستند.
موارد رایج استفاده از خوشهبندی و کاهش ابعاد شامل گروهبندی موجودی بر اساس دادههای فروش، مرتبط کردن دادههای فروش با مکان قفسه فروشگاه، دستهبندی شخصیتهای مشتری و شناسایی ویژگیها در تصاویر است.
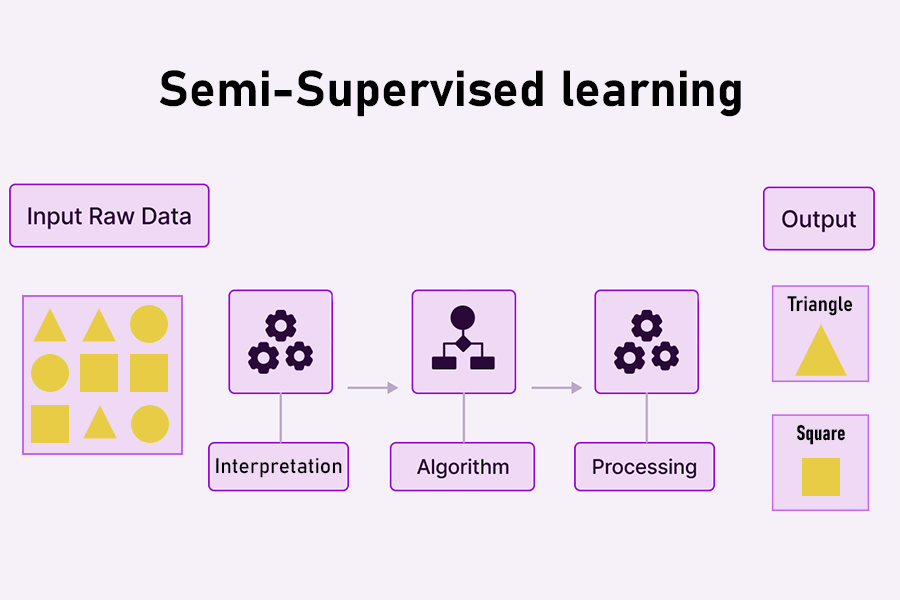
3. یادگیری نیمه نظارتی (Semi-supervised learning)
مدلهای یادگیری نیمهنظارتشده (نیمهنظارتی) فرآیندهایی را مشخص میکنند که از الگوریتمهای یادگیری بدون نظارت برای تولید خودکار برچسبهایی برای دادههایی استفاده میکنند که میتوانند توسط تکنیکهای نظارت شده مصرف شوند. برای اعمال این برچسبها میتوان از چندین رویکرد استفاده کرد، از جمله موارد زیر:
- تکنیکهای خوشهبندی (Clustering techniques)، دادههایی را برچسبگذاری میکنند که شبیه برچسبهای تولید شده توسط انسان به نظر میرسد.
- تکنیکهای یادگیری با نظارت خود (Self-supervised learning techniques)، الگوریتمهایی را برای حل یک وظیفه آموزش میدهند که به درستی برچسبها را اعمال میکند.
- تکنیکهای چند نمونهای (Multi-instance techniques) راههایی برای تولید برچسب برای مجموعه ای از نمونهها با ویژگیهای خاص پیدا میکنند.
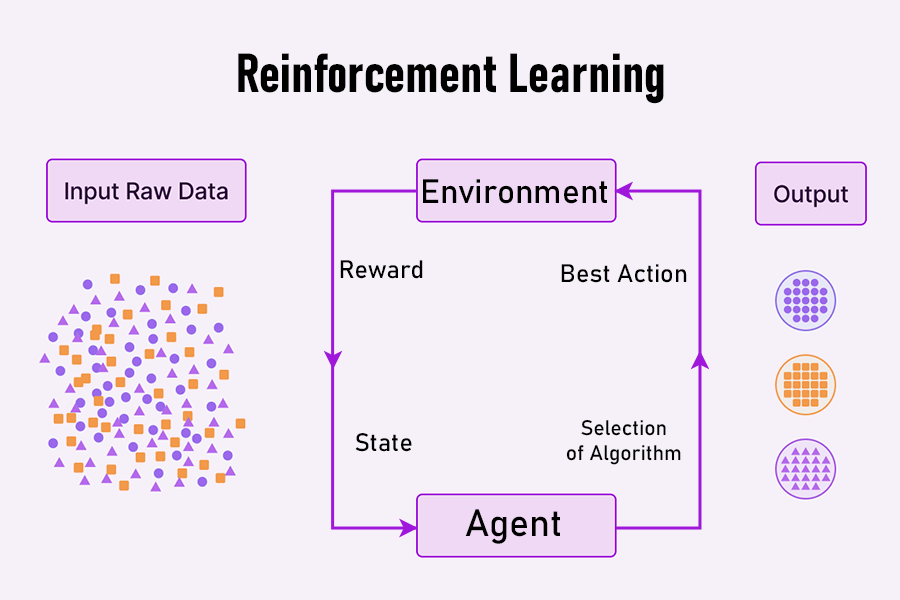
4. یادگیری تقویتی (Reinforcement learning)
مدلهای یادگیری تقویتی معمولاً برای بهبود مدلها پس از استقرار آنها استفاده میشود. این مدلها همچنین میتوانند در یک فرآیند آموزشی تعاملی، مانند آموزش الگوریتمی در انجام بازیها برای پاسخ به حرکات فردی یا تعیین برد و باخت در یک دور از بازیها مانند شطرنج، استفاده شوند.
تکنیک اصلی مستلزم ایجاد مجموعهای از اقدامات، پارامترها و مقادیر نهایی است که از طریق آزمون و خطا تنظیم میشوند. در هر مرحله، الگوریتم یک پیشبینی یا حرکت میکند و یا تصمیم میگیرد. نتیجه آن با نتایج یک بازی یا سناریوی واقعی مقایسه میشود. یک جریمه یا پاداش برای اصلاح الگوریتم در طول زمان ارسال میشود.
رایجترین الگوریتمهای یادگیری تقویتی از شبکههای عصبی مختلف استفاده می کنند. برای مثال، در برنامههای خودروهای خودران، آموزش الگوریتم ممکن است بر اساس نحوه واکنش آن به دادههای ضبطشده از خودروها یا دادههای مصنوعی باشد که نشاندهنده چیزی است که حسگرهای خودرو در شب میبینند.
انواع محبوبتر الگوریتمهای یادگیری ماشین
صدها نوع الگوریتم یادگیری ماشین وجود دارد که انتخاب بهترین رویکرد برای یک مسئله معین را دشوار میکند. علاوه بر این، گاهی اوقات می توان از یک الگوریتم برای حل انواع مختلف مسائل مانند طبقهبندی و رگرسیون استفاده کرد.
گواررا میگوید: «الگوریتمها نقشههای اساسی برای ساخت مدلهای یادگیری ماشین هستند. این الگوریتمها قوانین و تکنیکهای مورد استفاده برای یادگیری از دادهها را تعریف میکنند. آنها نه تنها منطق پیشپردازش و آمادهسازی دادهها، بلکه الگوهای آموزشدیده و آموختهشده را نیز در بر میگیرند که میتوان از آنها برای پیشبینی و تصمیمگیری بر اساس دادههای جدید استفاده کرد.
به نظر مایکل شهاب (Michael Shehab)، مدیر فناوری و نوآوری آزمایشگاهها در شرکت PwC، از آنجایی که دانشمندان علوک داده در چشمانداز الگوریتم یادگیری ماشین حرکت میکنند تا مهمترین حوزههایی را تعیین کنند که باید روی آن تمرکز داشته باشند، مهم است که معیارهایی را در نظر بگیریم که نشاندهنده سودمندی، وسعت کاربرد، کارایی و قابلیت اطمینان هستند. او همچنین بر توانایی یک الگوریتم برای پشتیبانی از گستره وسیعی از مسائل به جای حل یک کار واحد تأکید کرد. برخی از الگوریتمها در نمونه کارآمدتر هستند و به دادههای آموزشی کمتری نیاز دارند تا به مدلی با عملکرد خوب برسند، در حالی که برخی دیگر در زمان آموزش و استنتاج کارایی محاسباتی بیشتری دارند و به منابع محاسباتی مورد نیاز برای اجرای آنها نیاز ندارند.
شهاب گفت: «اصلاً بهترین الگوریتم یادگیری ماشین وجود ندارد. گزینه مناسب برای هر کمپانی و شرکتی گزینهای است که از طریق آزمایش و ارزیابی درست و غلط انتخاب شده باشد تا به بهترین وجه معیارهای تعریف شده توسط مشکل را برآورده کند.»

بعضی از محبوبترین الگوریتمها و مدلهایی که شرکتها با آن کار میکنند عبارتند از:
- شبکه های عصبی مصنوعی (Artificial neural networks ) شبکهای از نورونهای به هم پیوسته را آموزش میدهند که هر کدام از آنها الگوریتم استنتاج خاصی را اجرا میکند که ورودیها را به خروجیهایی تبدیل میکند که با گرهها در لایههای بعدی شبکه تغذیه میشوند. مدلهای یادگیری: بدون نظارت، نیمه نظارت و تقویتی.
- درختهای تصمیم (Decision trees ) یک نقطه داده را از طریق مجموعهای از آزمونها روی یک متغیر ارزیابی میکنند تا به یک نتیجه برسند. درختهای تصمیم معمولاً برای طبقهبندی و رگرسیون استفاده میشوند. مدل یادگیری: تحت نظارت.
- خوشهبندی K-means (K-means clustering ) فرآیند یافتن گروهها را در یک مجموعه داده خودکارسازی میکند که در آن تعداد گروهها با متغیر K نشان داده میشود. وقتی این گروه ها شناسایی شدند، هر نقطه داده را به یکی از این گروهها اختصاص میدهد. مدل یادگیری: بدون نظارت.
- رگرسیون خطی (Linear regression) رابطهای بین متغیرهای پیوسته پیدا میکند. مدل یادگیری: تحت نظارت.
- رگرسیون لجستیک (Logistic regression) با شناسایی بهترین فرمول برای تقسیم رویدادها به دو دسته، احتمال قرار گرفتن یک نقطه داده در یک دسته را تخمین میزند. معمولاً برای طبقه بندی استفاده می شود. مدل یادگیری: تحت نظارت.
- دستهبندیکننده بیز ساده (Naive Bayes) از قضیه بیز برای طبقهبندی مقولهها بر اساس احتمالات آماری استفاده میکند که نشاندهنده رابطه الگوها بین متغیرها در مجموعه داده است. مدل یادگیری: تحت نظارت.
- الگوریتمهای نزدیکترین همسایه (Nearest neighbors) به چندین نقطه داده در اطراف یک نقطه داده معین نگاه میکند تا دستهبندی آن را تعیین کند. مدل یادگیری: تحت نظارت.
- جنگلهای تصادفی (Random forests) مجموعهای از الگوریتمهای مجزا را سازماندهی میکند تا یک درخت تصمیمگیری را ایجاد کند که میتواند برای مسائل طبقهبندی اعمال شود. مدل یادگیری: تحت نظارت.
- بردار پشتیبانی (Support vector) دادههای از پیش برچسبگذاری شده را به دستهها فیلتر میکند تا مدلی را آموزش دهد که نقاط داده جدید را به دستههای مختلف اختصاص دهد. مدل یادگیری: تحت نظارت.
و در پایان این که…
در این مطلب به بررسی دقیق و کامل انواع یادگیری ماشین و الگوریتمهای آنها پرداختیم. اگر به دنبال استفاده از به روزترین محصولات هوش مصنوعی و یادگیری ماشین هستید، همین حالا از قسمت تماس با ما با آویر تماس بگیرید. ما در آویر با کمک متخصصان و نخبگان، بهترین محصولات را به شما ارائه میکنیم.
سوالات متداول در مورد انواع یادگیری ماشین
یادگیری ماشین زیرشاخهای از هوش مصنوعی است که به ماشینها قابلیت یادگیری و بهبود بر اساس دادههای ورودی را میدهد.
یادگیری ماشین به 4 دسته اصلی تقسیم میشود: یادگیری با نظارت (Supervised Learning)، یادگیری بدون نظارت (Unsupervised Learning) ، یادگیری نیمه نظارتی (Semi-supervised learning) و یادگیری تقویتی (Reinforcement Learning).
برای آموزش مدل یادگیری ماشین، ابتدا دادههای آموزشی و معیار ارزیابی لازم است. سپس مدل را با استفاده از الگوریتم مناسب و ابزارهای مرتبط آموزش میدهید.




